I recently had the need (for a side project) to be able to read a file written
from a .NET application using the BinaryWriter class from an application
written using Go. The MSDN documentation was somewhat vague on the format in
which strings were written, but it turns out to be a LEB128 encoded length
prefix and then the UTF8 bytes which make up the string.
The interesting part here is the length prefix. LEB128 is an encoding which uses the 7 low bits of a byte to represent the value, and the high bit to represent whether or not the next byte must be considered part of the value or not. This results in short strings only needing a single byte to encode the length, while the maximum number of bytes required to represent the length is five instead of four.
I wrote a package to decode these integers with test cases taken from a variety
of sources, including from Mono’s implementation of BinaryReader. The package
is available on GitHub.
The major test cases look like this:
var decodingTests = []struct {
in []byte
out uint32
}{
{[]byte{0x00}, 0},
{[]byte{0x01}, 1},
{[]byte{0x05}, 5},
{[]byte{0xFF, 0xFF, 0xFF, 0xFF, 0x07}, 2147483647},
{[]byte{0x80, 0x01}, 128},
{[]byte{0xE5, 0x8E, 0x26}, 624485},
}
func TestDecode(t *testing.T) {
for _, test := range decodingTests {
reader := bytes.NewReader(test.in)
decoded, err := Decode(reader)
if err != nil {
t.Fatalf("Error decoding LEB128 to uint32 (Input: %d): %s", test.out, err)
}
if decoded != test.out {
t.Errorf("Expected: %d, Actual: %d", test.out, decoded)
}
}
}
The actual code which reads from an io.Reader and produces a uint32 looks
like this:
//Decode reads a LEB128-encoded unsigned integer from the given io.Reader and returns it
//as a uint32.
func Decode(reader io.Reader) (uint32, error) {
var result uint32
var shift uint8
var current byte
for {
if err := binary.Read(reader, binary.LittleEndian, ¤t); err != nil {
return 0, err
}
result |= uint32(current&0x7F) << shift
if (current & 0x80) == 0 {
break
}
shift += 7
if shift > (4 * 7) {
return 0, errors.New(errMaximumEncodingLengthExceeded)
}
}
return result, nil
}
Now we can parse the length, reading the actual bytes of the UTF-8 string is straightfoward:
func ReadDotNetBinaryWriterString(reader io.Reader) (string, error) {
length, err := leb128.Decode(reader)
if err != nil {
return "", err
}
raw := make([]byte, length)
if err := binary.Read(reader, binary.LittleEndian, &raw); err != nil {
return "", err
}
return string(raw), nil
}
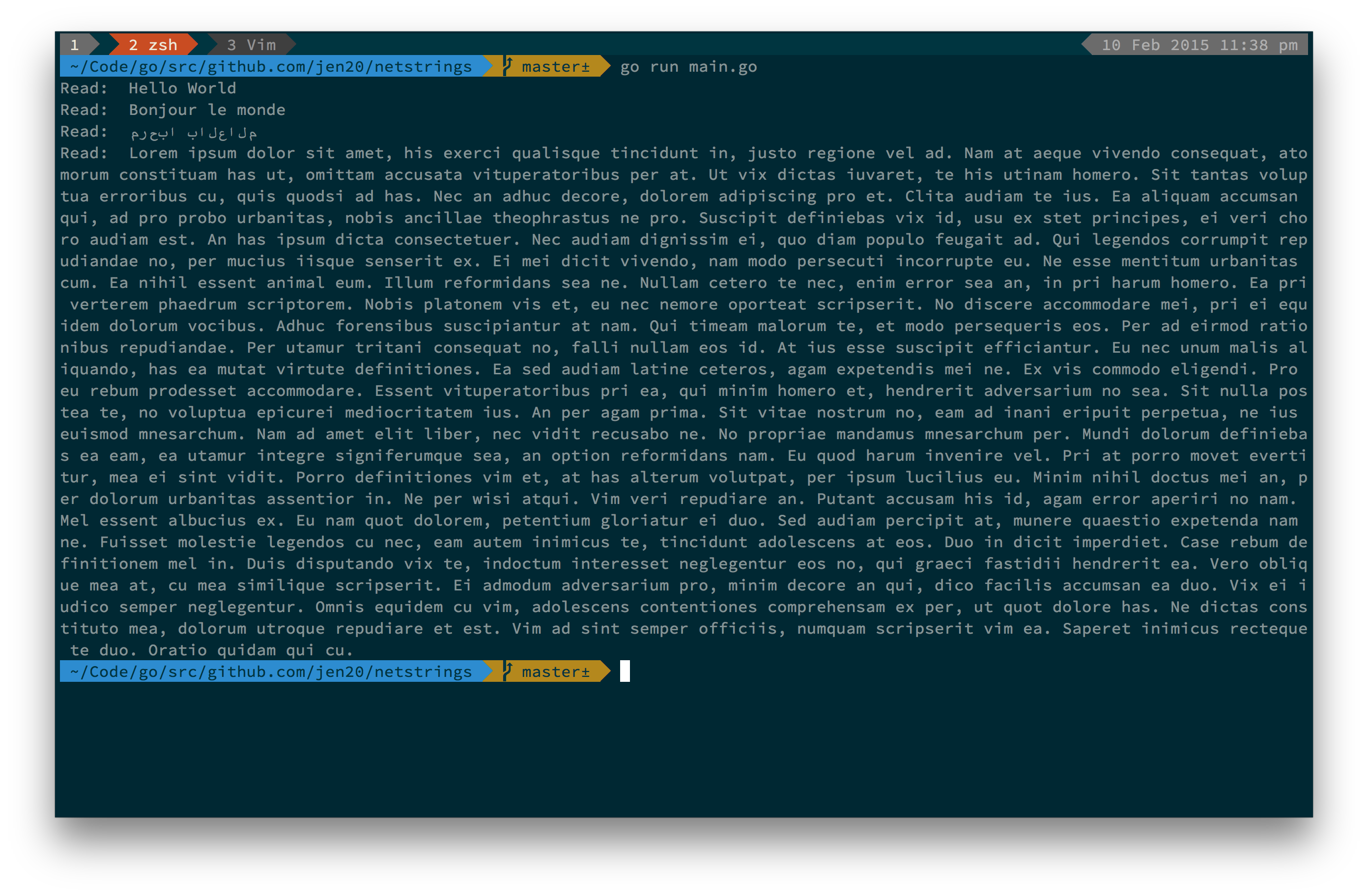
To verify this is working as expected (at least quickly) I wrote some strings
to a file using BinaryWriter from a C# program, and read them using the
following code:
func main() {
file, err := os.Open("strings.bin")
if err != nil {
panic(err)
}
for {
content, err := ReadDotNetBinaryWriterString(file)
if err != nil {
if err == io.EOF {
break
}
panic(err)
}
fmt.Println("Read: ", content)
}
}
The output looks like this: